概述
1. 定义和核心任务
自然语言处理(Natural Language Processing, NLP) 是人工智能(AI)领域的重要组成部分,它赋予计算机理解、解释、生成人类语言的能力,并基于这些能力对文本数据进行决策 。NLP 旨在弥合人类交流的模糊性、情境性和复杂性与计算机精确、形式化的指令系统之间的鸿沟。
NLP 通常可以概括为自然语言理解(Natural Language Understanding,NLU)与自然语言生成(Natural Language Generation,NLG)两类能力,这两者共同构成了机器与人类语言交互的完整闭环。自然语言理解负责“读懂”,也就是输入语言,输出结构化信息。它主要的目标是从非结构化的文本中提取意义,如识别意图、提取实体、分析情感等。例如,当用户输入“帮我订一张明天去上海的机票”,NLU 需要解析出“订票”意图以及“上海”“明天”等关键信息。另一方面,自然语言生成负责“说出”,即输入结构化信息,输出语言。它将计算机内部的数据与决策转化为人类可读的文本。
文本表示和词向量
1. 分词的定义和重要性
分词的任务,是把连续的文本序列切分成具有独立语义的基本单元(即“词”或“词元”)。对于英文等天然有空格作为分隔符的语言,分词相对简单。但对于中文、日文、泰文等语言,文本是连续的字符流,词之间没有明确的边界。
在传统的 NLP 处理流程中,分词是后续所有任务的基础。处理方式通常是将分词作为一个独立且“硬性”的预处理步骤,这就导致一个微小的分词错误就可能造成语义信息的丢失。这种错误会在后续的处理链条中被不断放大,产生“差之毫厘,谬以千里”的级联效应。
2. 基于规则和字典
基于规则与词典的分词方法是 NLP 领域最早期的技术方案,也是最符合人类直觉的分词方式。它的核心依赖于一部大型词典和一套匹配规则。jieba 的默认模式实现的就是这种方式。它会先基于一个前缀词典(Trie 树),高效地构建出一个包含句子中所有可能词语组合的有向无环图(DAG)。接着,通过动态规划算法寻找一条概率最大的路径,作为最终分词结果。这个过程可以被量化为一个概率计算问题。
3. 统计学习时代的方法
为了解决对人工词典的过度依赖,研究者们转向了统计学习。主要思想是把分词看作一个序列标注问题,即为句子中的每个字打上一个位置标签。 隐马尔可夫模型(HMM) 就是解决这类问题的经典生成式模型。它能学习到字与标签之间的对应关系(发射概率)以及标签与标签之间的转移关系(转移概率)。
从分词到分块
随着深度学习,特别是 BERT 和 GPT 等大规模预训练模型的兴起,传统意义上“将句子切分成标准词语”的分词范式有了重大改变。现代 NLP 模型更倾向于采用**“无分词”或“弱分词”的策略,将文本处理成更基础的、数据驱动的单元,主要分为字粒度和子词粒度**两种流派。
- 字粒度分词:以
BERT模型为代表,在处理中文时,它的分词策略就是字粒度,也就是直接将每个汉字视为一个独立的 Token。这种策略有效解决了 OOV 问题,因为常用汉字的数量是有限的,模型可以轻松构建一个全覆盖的“字表”,摆脱对庞大词典的依赖。但是,它的代价也显而易见。首先是词汇语义的丢失,像“博物馆”这样的词被拆散为三个独立的字后,模型需要消耗更多资源去重新学习它们之间的组合关系;其次,相较于词,字的序列长度会显著增加,这加大了模型的计算负担。 - 子词分词:以
GPT系列为代表的大语言模型,则采用了更灵活的子词(Subword) 切分方案,其中最主流的算法是 BPE(BytePair Encoding)。BPE 的思路是在原始语料上迭代合并高频相邻字节对(或字符对)成一个新的、更大的单元,并将其加入词表。这种方案在“词”和“字”之间取得了有效平衡,高频词被完整保留,低频词或新词则被拆解为更小的有意义单元(如字或字节组合),既保持了信息完整性又有效解决了 OOV 问题,同时还能通过控制合并次数来限制词表大小。
循环神经网络
1. RNN结构
循环神经网络(Recurrent Neural Network, RNN就是为满足这一需求而诞生的。RNN 的思想是在处理序列的每一步时,网络不仅接收当前时间步的输入 xtxt,还会接收一个来自上一步的“记忆”,即隐藏状态 ht−1ht−1。网络会将这两部分信息融合,生成当前步的输出 htht,并将其作为新的“记忆”传递给下一步。这种机制本质上是对全连接网络的改进,具体来说,模型会首先像全连接网络一样处理当前输入 xtxt 得到 U⋅xtU⋅xt,同时引入另一个全连接层处理来自上一步的隐藏状态 ht−1ht−1 得到 W⋅ht−1W⋅ht−1,最后将这两部分信息相加并通过一个激活函数(如 tanhtanh)得到当前步的隐藏状态 htht。如此一来,htht 就同时包含了当前输入 xtxt 的信息和之前所有步的信息“摘要” ht−1ht−1。
2.RNN局限性
- 梯度消失和梯度爆炸:在 RNN 中,权重矩阵 WW 的值通常会被初始化为较小的值,如果 W 的范数(可以理解为其对向量的缩放能力)小于1,或者激活函数的导数(如 tanh′最大为 1,通常小于 1)导致连乘项变小,那么多次相乘之后,梯度值会以指数级速度衰减,迅速趋近于 0,这就是梯度消失(Vanishing Gradients)。当序列很长时(t−k很大),来自遥远过去的梯度信号在传播到当前步时,几乎完全消失。反之,如果 WW 的范数大于 1,梯度值则会指数级增长,最终变成一个非常大的数值(Inf 或 NaN),导致模型训练崩溃,这被称为梯度爆炸(Exploding Gradients)。梯度爆炸问题相对容易发现和处理,一种常见的解决方法是梯度裁剪(Gradient Clipping),也就是当梯度的范数超过某个阈值时,就将其缩放到该阈值。
- 长距离依赖:模型无法捕捉到这种关键的远距离语义依赖。
- 常规 RNN 的信息流是单向的, tt 时刻的计算只能利用 tt 时刻之前的信息,无法利用未来的上下文信息。
注意力机制和transformer
1. seq2seq
在自然语言处理中,还存在一类更复杂的、被称为多对多(Many-to-Many, Unaligned) 的任务,它们的输入序列和输出序列的长度可能不相等,且元素之间没有严格的对齐关系。 为了解决这一挑战,2014年,研究者们提出了序列到序列(Sequence-to-Sequence, Seq2Seq) 架构,它成功地将一种通用的编码器-解码器(Encoder-Decoder) 架构应用于序列转换任务。
从自编码器到seq2seq
自编码器主要由两个部分组成。其中编码器负责读取输入数据(如一张图片、一个向量),并将其压缩成一个低维度的、紧凑的潜在表示 (Latent Representation) ,这个过程可以看作是特征提取或数据压缩。解码器则接收这个潜在表示,并尝试将其重构回原始的输入数据。自编码器的训练目标是让输出与输入尽可能地相同。通过这个过程,模型被迫学习到数据中最具代表性的核心特征,并将这些特征编码在潜在表示中。它的目标是数据重构,常被用于降维、特征学习或数据去噪等任务。
整体架构
Seq2Seq 的核心思想借鉴了人类进行翻译的过程,即先完整地阅读并理解源语言的整个句子,形成一个综合的语义表示,然后基于这个语义表示开始用目标语言逐词生成译文。它的目标是从 Input 到 Output 的转换,而非重构。模型同样被拆分为两个组件,其中编码器扮演“阅读和理解”的角色,负责接收整个输入序列,并将其信息压缩成一个固定长度的上下文向量(Context Vector) C,这个向量即为输入序列的“语义概要”。解码器则扮演“组织语言并生成”的角色,它接收上下文向量 C 作为初始信息,然后逐个生成输出序列中的词元。
2. 注意力机制
设计原理
注意力机制的原理,可以通俗地理解为从“一言以蔽之”到“择其要者而观之”的转变。它的原理是在解码器生成每一个词元时,不再依赖一个固定的上下文向量,而是允许它“回头看”一遍完整的输入序列,并根据当前解码的需求,自主地为输入序列的每个部分分配不同的注意力权重,然后基于这些权重将输入信息加权求和,生成一个动态的、专属当前时间步的上下文向量。
qkv范式
- 查询(Query):代表了当前的需求或意图。在 Seq2Seq 中,这就是解码器在生成下一个词元前的状态 ,可以理解为它在“查询”的是“根据我现在的情况,我最需要输入序列的哪部分信息?”
- 键(Key):可以看作是输入序列中各个信息片段的“标签”或“索引”,用于和查询进行匹配。在 Seq2Seq 中,输入序列的每个词元的隐藏状态 hjhj 都对应一个“键”。
- 值(Value):是与“键”对应的实际信息内容。在基础的注意力机制中,“键”和“值”通常是相同的,都来自于编码器的隐藏状态 hjhj。
无论形式如何变化,注意力机制的本质都可以概括为通过查询(Q)和一系列键(K)计算相关性(权重),然后利用这个权重,对与各个键对应的值(V) 进行加权求和,得到最终的输出。
具体计算过程,可以用一个凝练的数学公式来统一表达,这就是 缩放点积注意力(Scaled Dot-Product Attention) ,它也是 Transformer 模型的核心组件之一
Transformer
1. 自注意力机制
自注意力机制。它不再依赖于顺序计算,而是将提取序列特征的过程看作是输入序列“自己对自己进行注意力计算”。序列中的每个词元都会“审视”序列中的所有其他词元,来动态地计算出最能代表当前词元上下文含义的新表示。与上一节介绍的交叉注意力不同,在自注意力中,Query、Key、Value 均来源于同一个输入序列。
2. 自注意力计算过程
- 生成QKV向量 对于输入序列中的每一个词元,首先获取其词嵌入向量 xixi。然后,将该向量分别与三个可学习的、在整个模型中共享的权重矩阵 WQ,WK,WVWQ,WK,WV 相乘,生成该词元专属的 Query 向量 qiqi、Key 向量 kiki 和 Value 向量 vivi。 这三个矩阵的作用是将原始的词嵌入向量投影到不同的、专门用于注意力计算的表示空间中,赋予了模型更大的灵活性。
- 计算注意力分数 为了计算第 ii 个词元的新表示,需要用它的 Query 向量 qiqi 去和所有词元(包括它自己)的 Key 向量 kjkj 计算点积,得到注意力分数。
- 放缩和归一化 将得到的分数除以一个缩放因子 dkdk(dkdk 是 Key 向量的维度),然后通过 Softmax 函数进行归一化,得到最终的注意力权重 αijαij。这个缩放步骤的目的与上一节中介绍的一致,都是为了在训练过程中保持梯度稳定。当向量维度 dkdk 较大时,点积结果的方差会增大,可能将 Softmax 函数推向其梯度极小的区域,从而导致梯度消失,影响模型学习。进行缩放可以有效缓解这个问题。
- 加权求和 使用计算出的权重 αijαij 对所有词元的 Value 向量 vjvj 进行加权求和,得到第 ii 个词元经过自注意力计算后得到的新表示 zizi。
通过这个过程,输出向量 zizi 不再仅仅包含原始词元 xixi 的信息,而是融合了整个序列中所有与之相关词元的信息,成为一个上下文感知的、更丰富的表示。其本质可以理解为:序列中的每个词元都同时扮演着“查询(Q)”、“键(K)”和“值(V)”三种角色。通过计算查询与其他所有词元的键之间的相关性,来决定如何加权融合所有词元的值,从而为每个词元生成一个全新的、深度融合了全局上下文信息的表示。
3. transformer 架构
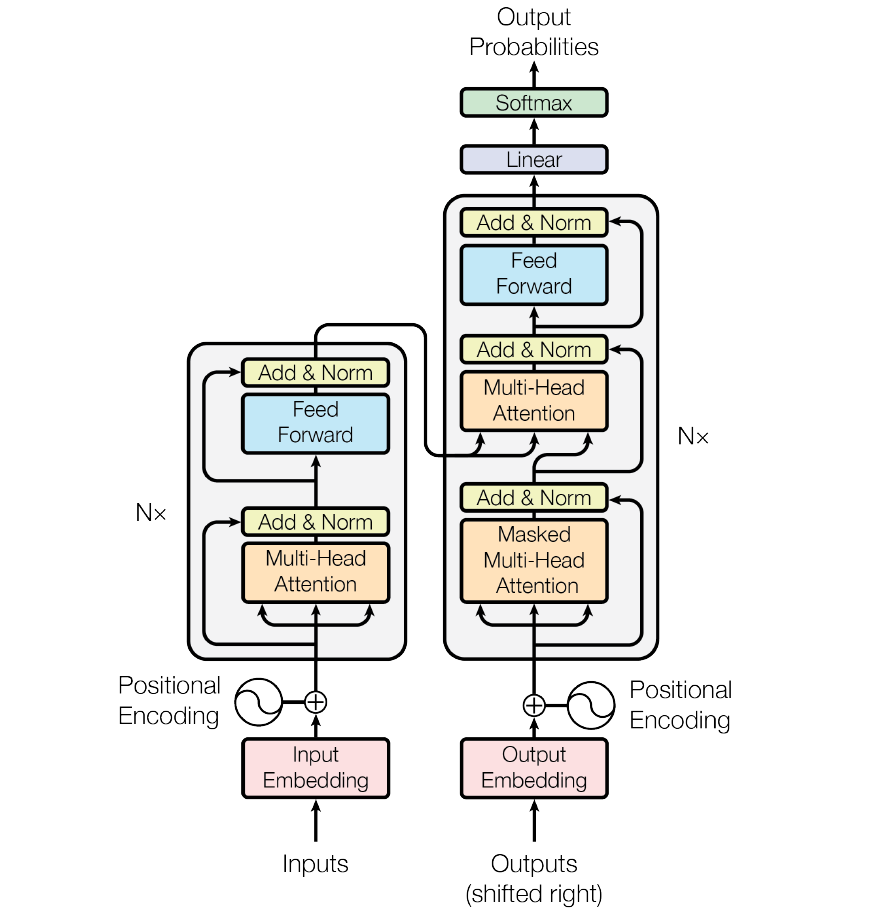 Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder)。
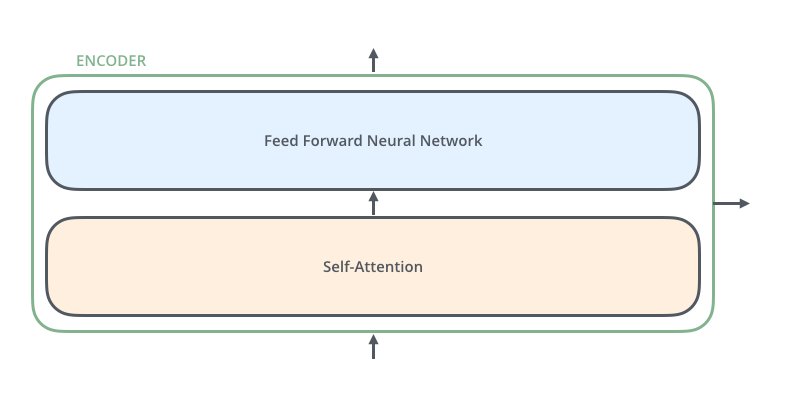
encoder:
单层encoder主要由以下两部分组成,
Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder)。
encoder:
单层encoder主要由以下两部分组成,
-
Self-Attention Layer
-
Feed Forward Neural Network
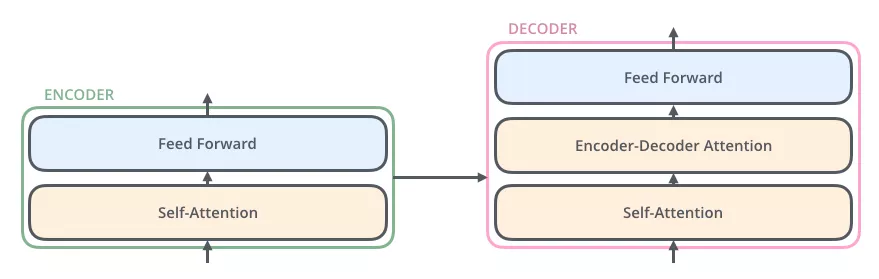
 与编码器对应,如下图,解码器在编码器的self-attention和FFNN中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分
与编码器对应,如下图,解码器在编码器的self-attention和FFNN中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分
4. transformer 结构细节
词向量:先会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维。 位置向量:Transformer模型对每个输入的词向量都加上了一个位置向量。这些向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征。词向量加上位置向量背后的直觉是:将这些表示位置的向量添加到词向量中,得到的新向量,可以为模型提供更多有意义的信息,比如词的位置,词之间的距离等。 编码器encoder: 编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量,这组序列向量会作为解码器的K、V输入,其中K=V=解码器输出的序列向量表示。这些注意力向量将会输入到每个解码器的Encoder-Decoder Attention层,这有助于解码器把注意力集中到输入序列的合适位置 Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分 Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。